Так получилось, что на момент начала написания этой статьи я проходил курс по анализу систем, отзыв на который я напишу потом отдельно в формате поста в свой телеграм-канал. Курс дал мне огромный пласт новой информации, которую я буду ещё год изучать и пытаться использовать уже как архитектор систем, но уже есть кое-что, что я успел изучить и даже успешно применить.
В статье я использую термин «модуль», который пришёл к нам из ООП и означает набор классов и функций, решающих конкретную задачу. Это не модуль из контекста каких-нибудь CRM/CMS и не модуль из контекста архитектурного стиля модульного монолита. Я также использую термин «класс», который можно легко заменить на «компонент».
Архитектор при анализе системы должен определить набор характеристик системы в целом, так и характеристики отдельных её компонентов. Одной из таких характеристик является Modifiability, которая складывается из множества разных факторов, но в целом говорит о том, насколько тяжело вносить изменения в систему и насколько легко сделать так, чтобы бизнес был доволен, когда приносит на разработку новую функциональность. И сюда же идёт характеристика **Agility **, которая не о том, легко ли изменять код, а о том, насколько сложно выкидывать неактуальное и добавлять актуальное, когда бизнес эволюционирует под новые реалии.
Проверить это можно разными способами: например, анализ закрытия задач в тасктрекере также может рассказать, насколько долго привозить новое и удалять старое, но в этом анализе слишком много человеческого влияния, он не даёт какой-то полной картины происходящего. Задача долго делалась, потому что разработчик был в больном состоянии и работал через силу, вместо того, чтобы взять больничный? Или разработчик не обладал должными компетенциями и, по сути, на этой задаче обучался? А может быть задача была сделана быстро, потому что разработчик решил, что можно просто написать код в контроллере, наплевав на поддерживаемость и когнитивную и цикломатическую сложности?
Ранее я даже и не догадывался, что существуют соответствующие качественные и количественные метрики, которыми можно покрыть кодовую базу проекта, получить цифры, нарисовать какие-то графики по этим цифрам, да и вообще анализировать в автоматическом режиме в CI и выдавать ошибку, если какое-то правило не прошло проверку.
При погружении в эту тему, я изначально искал возможность узнать, насколько модуль с компонентами сосредоточен на решении одной конкретной задачи — это про cohesion; и насколько сильно этот модуль связан с другими модулями — это про coupling. Конечно, можно было бы потратить уйму времени, чтобы изучить кодовую базу проекта, написанную другими разработчиками, оценить её «на глазок», но я ленивый, я хочу, чтобы оно вжух-вжух само. Автоматические метрики мне подошли бы кстати.
Ищем инструменты
Сразу же оговорюсь: я не теоретик, а практик. Я хочу что-то установить готовое, сконфигурировать и посмотреть, что получилось в итоге. Я нашёл огромное количество статей с теорией и отсылками к Роберту Мартину, где считают всякое через довольно элементарные формулы, но всё это теория. Теорию, к сожалению, в чистом виде нельзя сконфигурировать и натравить на кодовую базу, поэтому я полез искать существующие инструменты, реализующие эту самую теорию.
Для моего стека самого современного PHP, в который понапихали уже кучу всего полезного и интересного, я нашёл всего лишь 3 инструмента (если вы знаете какие-то хорошие, дайте знать) и остановился на одном из них.
PDepend оказался довольно странным, не учитывающим самые свежие фишки языка, рассматривающим каждый класс в отдельности и не умеющим анализировать модули. Выдаёт отчёт в не совсем удобном виде — отдельные графики в SVG, сам отчёт в XML и не имеет никакой визуализации всего отчёта в едином месте. К тому же анализировать каждый класс в отдельности — довольно глупая затея, которая не показывает ничего полезного и не позволяет рассмотреть проект как единый решающий конкретную задачу или набор задач юнит.
AST Metrics оказался самым новым, но содержит небольшое количество нужных мне метрик и почему-то не имеет отображения детализации по модулям, как другой инструмент от того же автора. Автор в своей дорожной карте отметил все задуманные метрики как завершённые, но, если сравнивать с первым его инструментом (о нём ниже), то увидим гораздо больше выдаваемой полезной информации.
PhpMetrics, на котором я в итоге и остановился, показывает довольно много разного интересного, прекрасно понимает модули, даже считает готовый Modifiability, но сам по себе инструмент не пользуется популярностью. Есть риск, что, так как автор забросил этот проект, отдал в опенсорс и занялся вторым проектом, поддержка инструмента закончится в самый неподходящий момент, и код на PHP 8.4, в котором будет расширен синтаксис, невозможно будет проанализировать.
Также есть ненулевая вероятность, что придётся делать свои инструменты, что я очень хочу до последнего оттягивать, чтобы не получить себе в поддержку ещё один проект. Я ещё не готов к такому морально.
Сгенерированный отчёт вывалил на меня огромное количество цифр, с частью из которых я уже был так или иначе знаком и имел представление, что показывают эти цифры. Тем не менее с некоторыми из них пришлось разбираться отдельно. Итак, погнали.
Что можно считать
Афферентные связи
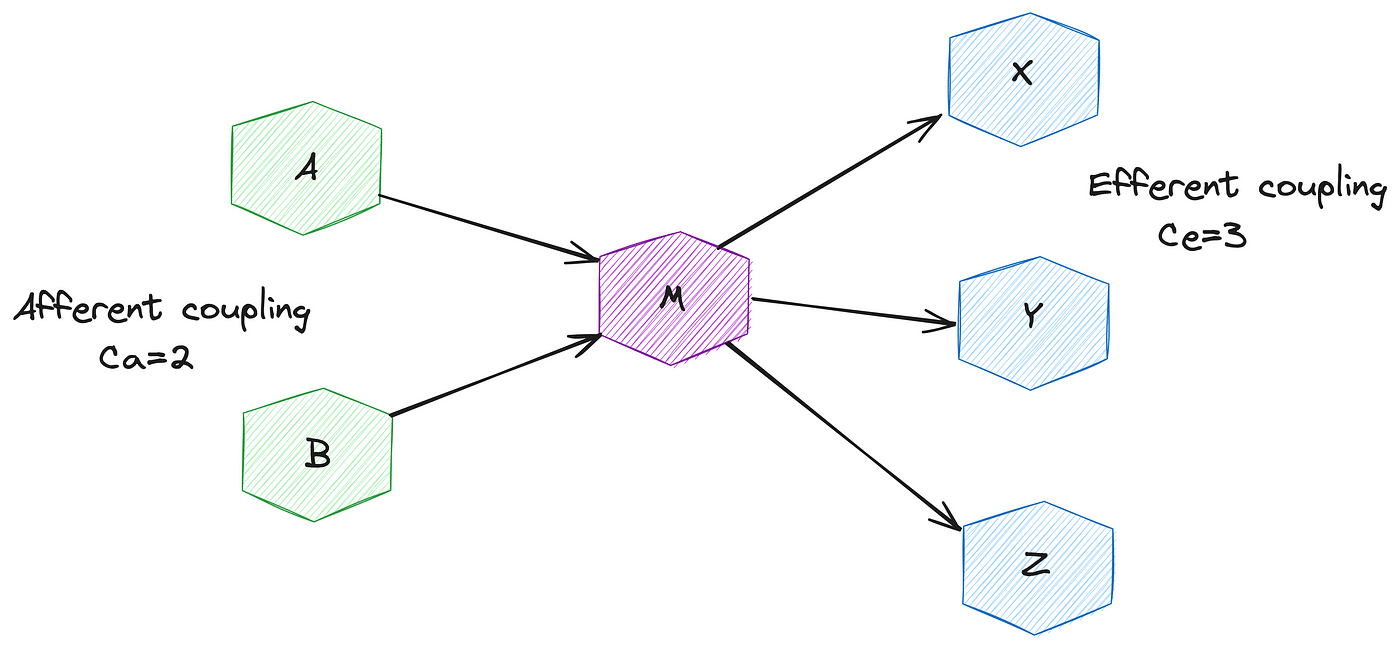
Афферентные связи (afferent coupling, входящие связи) записываются кратко как Ca и представляют собой простую сумму всех классов, которые используют внутри себя класс, для которого считаются связи. Проще говоря, если какой-то класс где-то импортирует класс, для которого считается метрика, то это даёт нам +1 к Ca.
Здесь есть один очень неявный нюанс, из-за которого мне пришлось хорошенько поломать голову и перерыть множество математических объяснений: метрика работает очевидным образом для композиционных связей. Но как быть с наследованием?
Можно предположить, что у суперкласса Ca равен количеству прямых наследников, однако, насколько я смог понять, в контексте межмодульных связей абстрактный класс — всегда должен быть частью того модуля, в котором находятся и наследники этого абстрактного класса, поэтому с точки зрения абстрактного класса — его никто не использует по прямому назначению, то есть не создаёт его экземпляры. Спорная вещь, я бы даже сказал контекстуально зависимая, но в стандартах метрик я нашёл именно это объяснение. Кто я такой, чтобы спорить с Робертом Мартином, верно?
Что же эта метрика даёт? Что в таких связях плохого или хорошего?
Да ничего ни плохого, ни хорошего, хотя на эту метрику уже можно накинуть какие-то проверки, но я бы отдельно эту метрику не рассматривал.
Эфферентные связи
Эфферентные связи (efferent coupling, исходящие связи) записываются кратко как Ce и представляют собой не менее простую сумму всех модулей, которые используют внутри себя класс, для которого считается метрика. То есть, считаем количество уникальных классов в коде рассматриваемого класса, каждый из которых даёт нам +1 к Ce.
А тут что плохого и хорошего?
Да тоже ничего плохого и хорошего. Всё это нам потребуется дальше.
Визуально это можно представить вот такой картинкой (считаем метрики для центрального модуля M):
В книге Fundamentals of Software Architecture Марка Ричардса и Нила Форда есть вот такая сноска:
Почему две важнейшие метрики в мире архитектуры, представляющие противоположные концепции, имеют практически одинаковые названия, отличающиеся всего лишь гласными с очень похожим звучанием? Эти понятия впервые появились в книге Йордона и Константина «Structured Design...». Позаимствовав понятия из математики, они ввели теперь уже широко распространенные термины афферентной и эфферентной связанности, которые следовало бы назвать входящей и исходящей связанностью. Но, поскольку авторы первоисточника имели склонность к математической симметрии, а не к ясности, разработчики придумали несколько мнемонических правил: буква «a» появляется в английском алфавите перед буквой «e», что соответствует тому, что входящие предшествуют исходящим; или, другой вариант, первая буква («e») в слове «efferent» та же, что первая букве в слове «exit» (выход), что соответствует исходящим соединениям.
Instability
И вот у нас есть на руках две цифры, с которым непонятно, что делать. Если рассматривать их в разрезе каждого отдельного класса, то окажется, что метрики действительно не очень-то и полезные. Мы не можем по ним сделать каких-то выводов, и это ничем не отличается от того, как если бы мы изучали всю кодовую базу руками и глазами.
Однако, если отдалиться от одного класса и рассматривать набор классов как модуль, ответственный за конкретную задачу, то мы можем предположить, что, чем больше входящих и исходящих связей, тем больше рассматриваемый модуль сцеплен со всем остальным кодом. И вот эти цифры можно уже начать как-то ограничивать. По крайней мере попытаться.
Раз мы знаем входящие и исходящие связи, то мы можем посчитать ещё одну метрику — Instability.
Метрика имеет диапазон [0, 1] и показывает степень подверженности изменениям рассматриваемого класса (или модуля) при изменении его зависимостей, которые мы посчитали ранее в виде исходящих связей — Ce.
Рассчитывается по очень простой формуле:
Instability = Ce / (Ce + Ca)
«Чё», — сказал я и пошёл разбираться.
Почему в формуле фигурирует Ca? Насколько я понял из объяснений, он позволяет рассматривать «стабильность», а если точнее «нестабильность» модуля, относительно частей системы, где этот модуль используется. Есть подозрения, что автор этой метрики не придумал название и подобрал максимально похожее под закладываемый смысл. Но вышло не очень и без понимания путает.
Важно отметить, что метрика не абсолютная, то есть 1 — это не 100% шанс того, что придётся править код, если что-то изменилось в другой части системы. Она лишь позволяет прикинуть, как относительно всей системы рассматриваемый модуль связан с остальной частью системы — относительно самого модуля.
Значение 0 означает, что модуль сосредоточен сам на себе, не зависит ни от каких других модулей, а значит «стабилен». Если другие модули изменятся, то это вообще никаким образом не повлияет на этот модуль. Именно этот смысл закладывается в «стабильность».
Значение 1 же в свою очередь означает, что модуль зависит от каких-то других модулей, при этом от этого модуля не зависит никто, а значит этот модуль «нестабилен». Цифра, отличная от нуля, даёт понимание, что здесь есть зависимости, изменение которых, возможно, приведёт к тому, что модуль (класс или классы в модуле) придётся также изменять под новые требования.
«Чё», — сказал я и придумал простой пример.
Чтобы лучше осознать метрику, можно представить на пальцах простую ситуацию (здесь я для простоты обобщаю классы и их экземпляры в виде объектов): если в классе А используется другой класс Б, то между этими классами существует некоторый контракт: класс Б предоставляет набор API-методов для работы с собой, а класс А, для которого мы считаем метрику, использует эти методы из API класса Б. Из этого примера можно сделать простые выводы:
- если контракт класса Б поменяется, то потребуется также поменять работу с этим контрактом и в классе А. По формуле расчёт для класса А получается вот таким: Instability = 1 / (1 + 0) = 1, то есть класс А «нестабилен»;
- если класс А поменяется, то это никак не отразится на классе Б. И по той же формуле расчёт для класса Б получается вот таким: Instability = 0 / (0 + 1) = 0, то есть класс Б «стабилен».
«Чё», — сказал я, но уже более тихо.
По этой метрике уже можно сложить некоторое понимание по существующим связям и прикинуть, как сильно связаны модули с остальной частью системы, чтобы хоть как-то сформировать представление, не анализируя и не выстраивая эти связи руками.
Может сложиться впечатление, что 0 — наш бро, а наличие 1 требует рефакторинг и следует трубить тревогу. Это неверные выводы. Если вся наша система будет состоять из наборов модулей с Instability = 0, то система просто не будет работать, потому что компоненты этой системы никак друг с другом не взаимодействуют — система бесполезна и ничего не делает. А Instability = 1 всего лишь означает, что есть модули, которые связывают другие модули воедино.
Эту метрику ни в коем случае нельзя рассматривать в вакууме. Нужно всегда представлять, какую задачу решает компонент и, например, стремящееся к 1 значение для оркестристрирующего медиатора — это наоборот хорошо, чем стремящееся к 0. А в случае с доменом заказа интернет-магазина стремящееся к 1 значение показывает, что модуль рассредоточен настолько сильно, что изменения в других местах потребуют правок в модуле заказа, и поэтому в данном случае следует стремиться к 0.
Так как же нам понимать — 0 здесь должен быть или 1, чтобы все были довольны? Погнали дальше, это ещё не всё.
Абстрактность
Очень простая метрика, которая показывает, насколько много абстрактных классов находится внутри модуля, относительно всех классов модуля.
Метрика рассчитывается по формуле:
Abstractness = AbstractClasses / TotalClasses
Примечателен тот факт, что интерфейсы также учитываются в расчёте. И, если в языке нет ни интерфейсов, ни абстрактных классов, придётся понимать абстрактность какими-то другими средствами, присущими конкретному языку и являющимися его особенностями, так как сама по себе абстрактность как явление никуда не исчезает. Сорри.
А она-то что даёт?
Да ничего, это просто цифра. Мы её считаем только для того, чтобы использовать в более осознанной метрике.
Distance from the main sequence
Наконец-то мы дошли до того, что свяжет высчитанное ранее в единую картину и поможет ответить на вопрос: насколько у нас всё в кодовой базе плохо или хорошо! Как всегда, не обойдётся без нюансов, но обо всём по порядку.
Для начала следует упомянуть Stable Abstractions Principle, который гласит, что в утрированном случае модуль должен быть или абстрактен и «стабилен», или конкретен и «нестабилен».
Абстрактный «нестабильный» код — это бесполезный код, который непонятно зачем выделили в отдельный модуль.
Конкретный «стабильный» код — это жёстко связанный со всей системой модуль, который крайне сложно изменять без изменения других модулей и который сложно распиливать.
Вернёмся к цифрам, которые получили ранее. У нас есть на руках высчитанные входящие в модуль связи, у нас есть исходящие из модуля связи. У нас есть рассчитанная «стабильность» и «абстрактность». Подставим это всё в очередную формулу:
Distance = | Abstractness + Instability - 1 |
И получим некоторое значение в диапазоне [0, 1].
Чтобы объяснить, что же за цифру мы получили и как её воспринимать, следует сначала показать вот такую картинку:
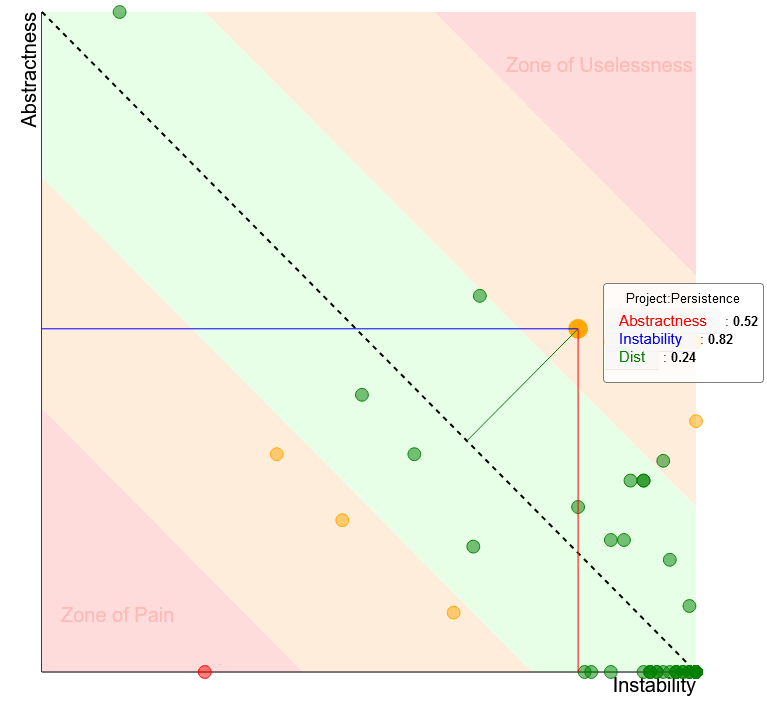
Если кратко, то полученное значение должно располагаться в идеале вдоль диагональной линии — той самой The Main Sequence, и построенный перпендикуляр от линии до модуля в виде точки и будет той самой высчитанной по формуле дистанцией.
И вот здесь происходит та самая математическая магия, которая позволяет нам судить о том, что происходит в коде: как хорошо модуль сосредоточен на происходящем в нём, сильно ли много зависимостей у модуля (не в количественном эквиваленте, а в качественном), есть ли абсолютно бесполезный код, который следовало бы выпилить. Это именно то, ради чего мы всё это затевали! Вакуумизированные цифры стали работать на нас!
Зелёная зона
Итак, зелёная зона — это модули, которые хорошо спроектированы и содержат приемлемые уровни «абстрактности» и «нестабильности». Они хорошо сосредоточены на выполнении своей задачи. Чем дальше по перпендикуляру от диагональной линии, тем больше сложность модуля и тем сложнее его поддерживать, но всё в пределах погрешности зелёной зоны.
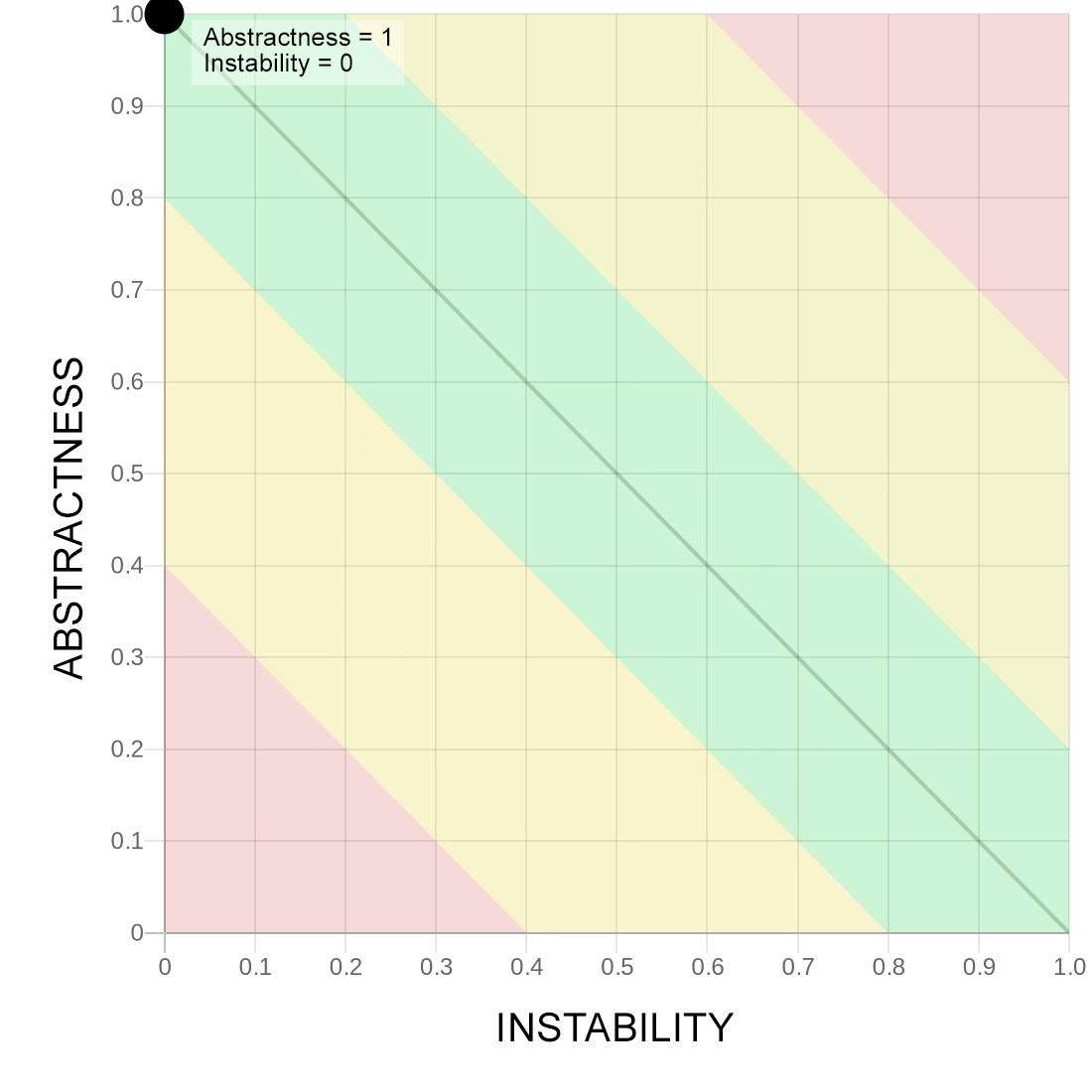
На изображении выше в левом верхнем углу располагаются такие модули, которые мало от чего зависят или не зависят вовсе (нет или мало исходящих связей), но при этом абстрактны — это нормально, так как мы помещаем в абстракцию то, что часто менять не нужно, это хорошая абстракция.
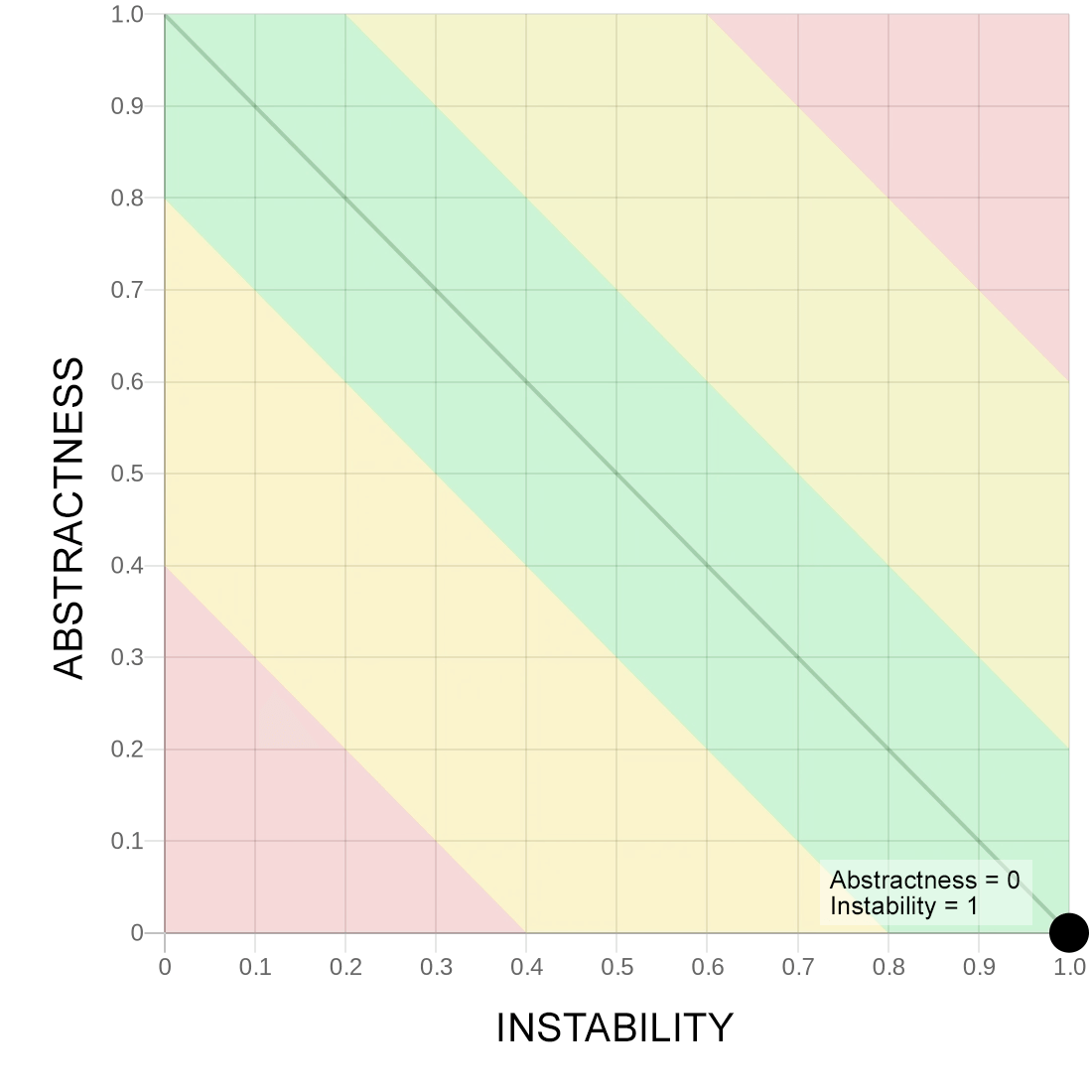
Выше в правом нижнем располагаются конкретные модули без абстракций, но которые хорошо сосредоточены на связывании остальных модулей, при этом от самих модулей никто не зависит (нет или мало входящих связей).
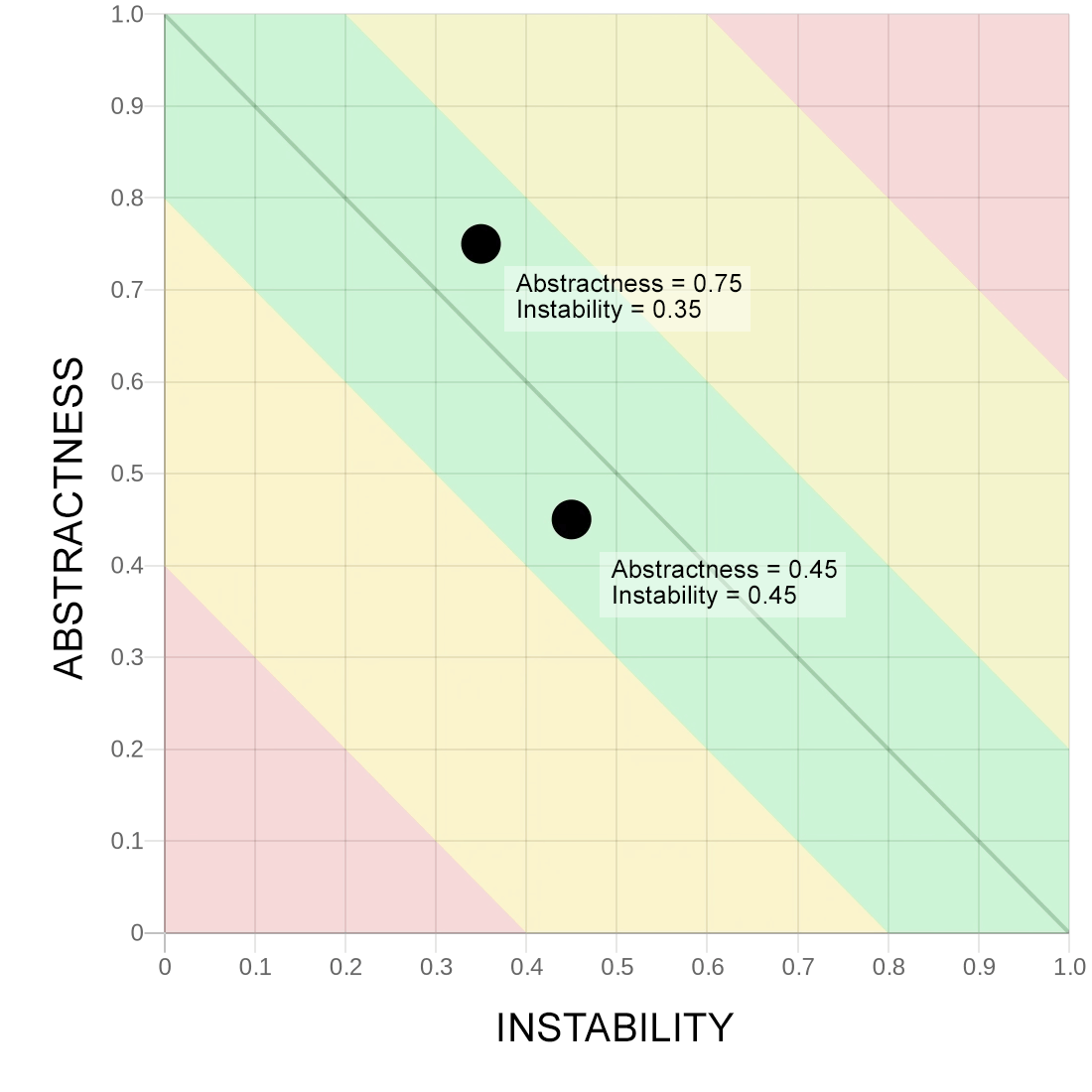
Между этими углами вдоль диагонали располагаются модули, которые содержат абстрактность и нестабильность в адекватном виде, так как совершенно всё сделать абстрактным и стабильным или конкретным и нестабильным попросту невозможно.
По формуле и графику видно, что Abstraction + Instability должны в идеале давать 1 или около неё, чтобы попасть в зелёную зону.
Жёлтая/оранжевая зона
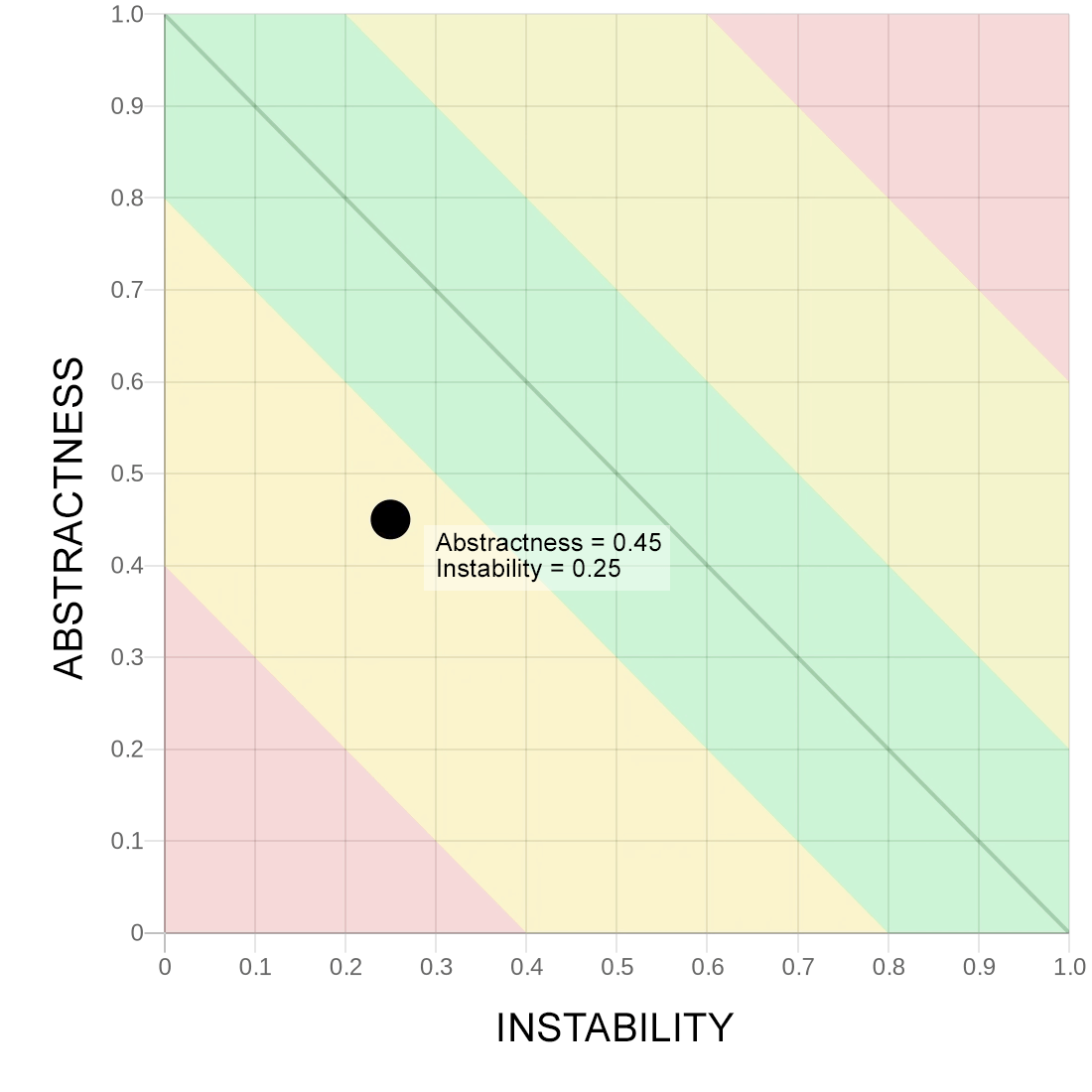
Здорово, теперь дальше: жёлтая или, как на первой картинке, оранжевая зона — зона повышенного внимания, которая сигнализирует о том, что, возможно, какие-то модули требуют рефакторинг, то есть их задачи то тут, то там решают куски из других модулей. Или же сами модули решают задачи чужих модулей.
У этих модулей, возможно, пониженный cohesion и повышенный coupling, что даёт нам сложности в поддержку: потребуется потрогать множество мест при изменениях в системе.
Зона боли
А что в красной и почему их две?
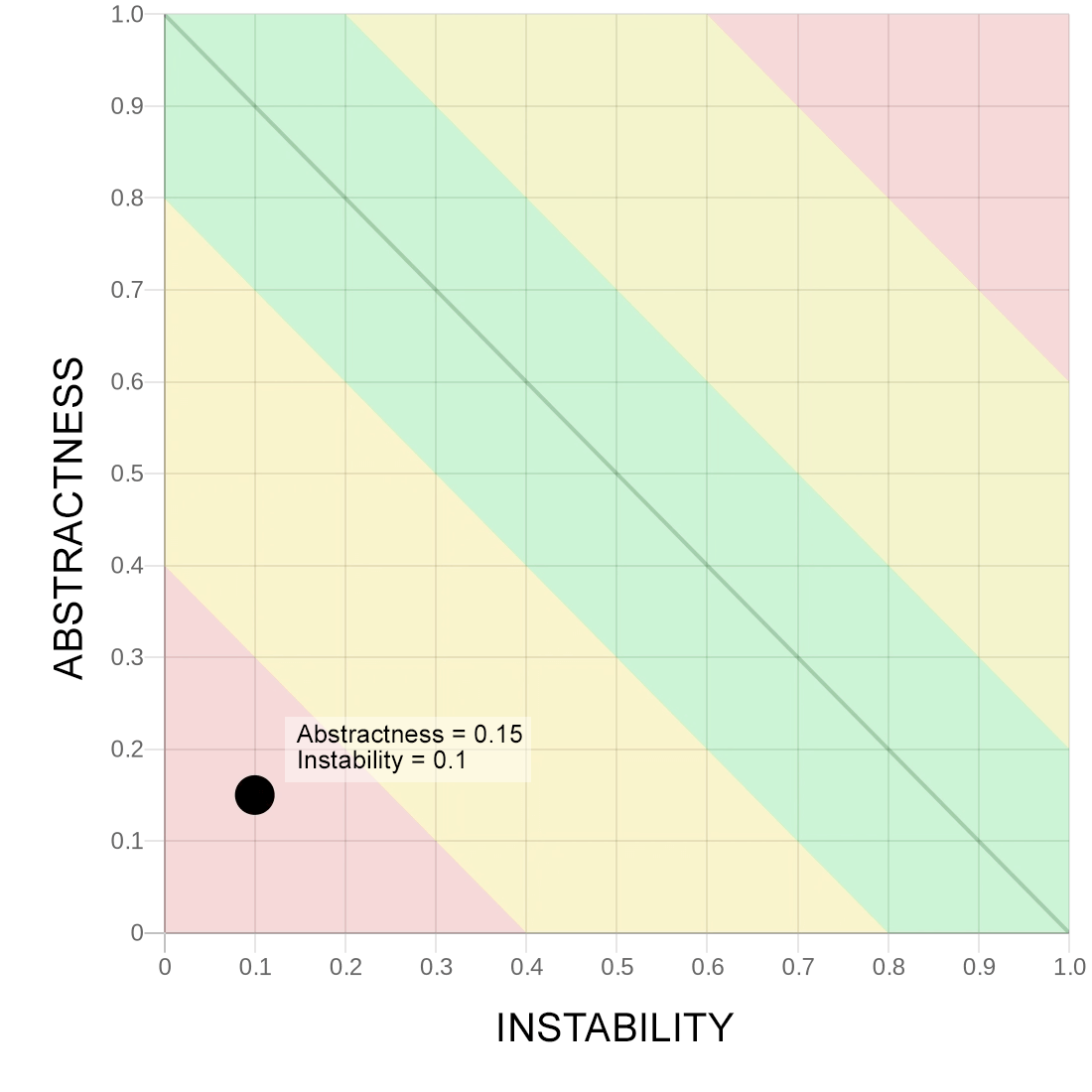
Если модуль конкретен, то есть содержит минимум «абстракции», и при этом «стабилен», то есть не зависит ни от чего, — это значит, что код хорошо сосредоточен сам на себе (high cohesion), однако, этот код скорее всего используется в других местах системы (high coupling). А значит изменения в этом модуле затрагивают огромный каскад в системе — трогаем этот модуль, после этого трогаем и все остальные модули. Это необязательно всегда будет так, но будет часто. И будет больно.
В качестве примера можно привести отделённый пакет с общими компонентами — утилитарными или набор общих доменных ValueObject. Тут стоит задуматься: а точно ли такой пакет нужен? Может быть утилиты расположить в местах, где они используются? Может быть ValueObject не стоит выделять и это, всё-таки, семантически разные ValueObject? Заставляет задуматься.
Однако, может так оказаться, что выделение пакета в отдельный Core-Domain с действительно общими доменными компонентами — это оправданный архитектурный ход. В этом случае принимаем как данность: да, мы осознанно сделали это, все всё понимают, риски известны.
Зона бесполезного кода
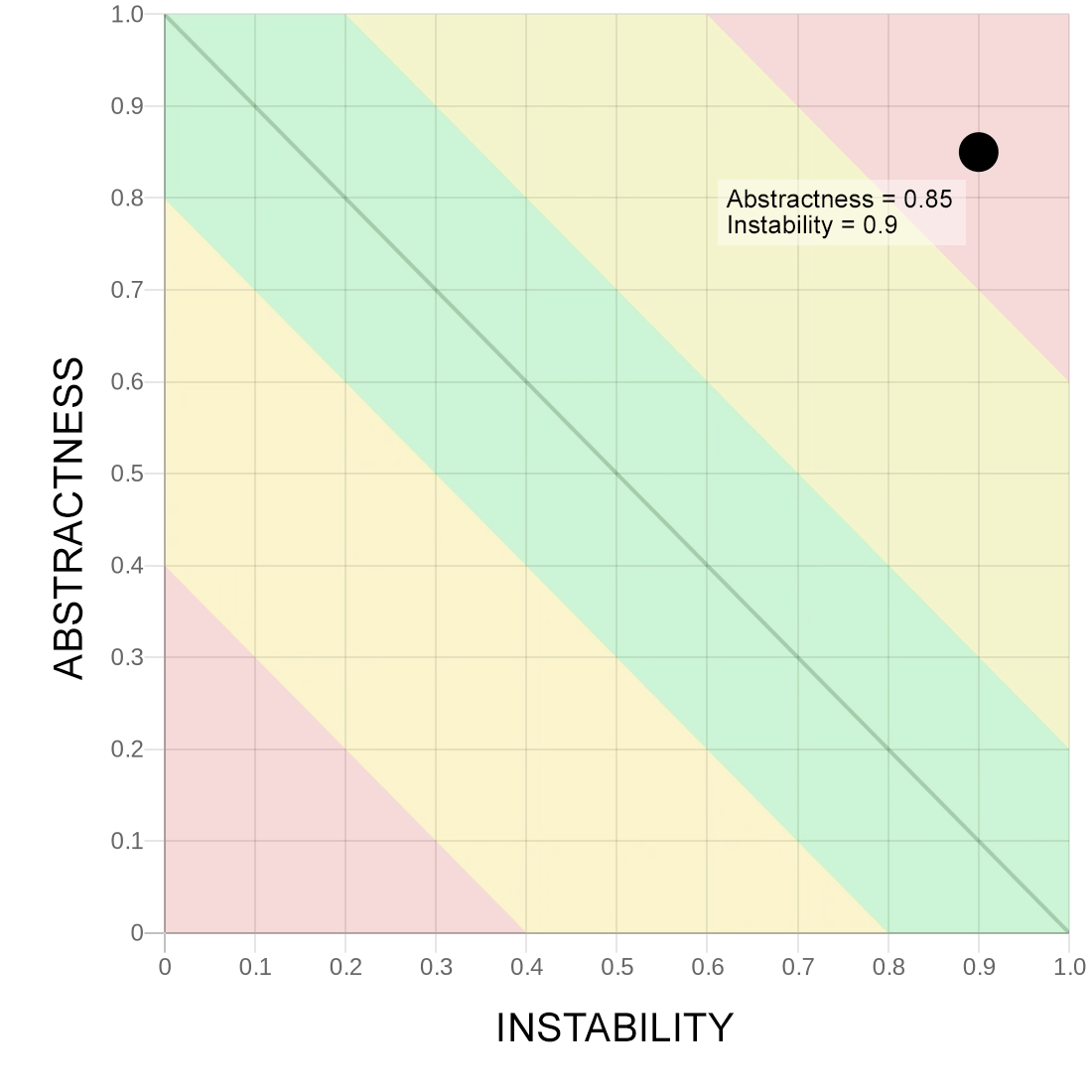
Хорошо, с левым нижним углом разобрались, переходим к правому верхнему. Если модуль абстрактен и при этом он «нестабилен», то есть в нём много зависимостей от других модулей, то такой модуль улетает в зону бесполезного кода. Это такой модуль, который напрямую нигде не используется, но при этом имеет зависимости от других… и возникает вопрос, почему мы его вырезали в отдельный модуль из конкретных мест, где этому коду самое место?
Здесь мы можем получить две ситуации. Первая заключается в том, что абстрактный код не имеет наследников. Тогда это действительно бесполезный, он же «мёртвый», код, от него следует избавляться, если наследники даже не планируют появляться в ближайшем будущем. Вторая ситуация вытекает из того, как считается афферентные связи (входящие связи, Ca) для абстрактных классов: в эту метрику не попадают наследники.
Если с первой ситуацией всё ясно — «мёртвый» код бесполезен, то со второй не так всё однозначно. Мы можем выделить в отдельный пакет инфраструктурные абстрактные компоненты для более удобной интеграции с инфраструктурой проекта, например абстрактные тайпкасты для интеграции в ORM-библиотеку. При этом в пакете будут только «абстрактные» «нестабильные» классы, так как они действительно инкапсулируют в себя возню с инфраструктурой, при этом имеют эфферентную (исходящие связи, Ce) зависимость от этой самой инфраструктуры.
Отделение куска функциональности в отдельные промежуточные модули-мосты может вызывать соответствующие вопросы, но, опять же, не всегда плохо. И снова мы можем принять такую ситуацию как данность: да, мы осознанно сделали это, все всё понимают, риски известны, всё под контролем.
Подытожив
Метрика Distance from the main sequence позволяет проанализировать все модули в проекте довольно прямым математическим методом. Это очень полезная метрика, которая может превентивно показать проблемы в коде, а также показать эволюцию кода в динамике, если сравнить две и более метрик, взятых в разное время.
На эту метрику можно навесить соответствующие реакции, чтобы своевременно реагировать на ухудшение метрики для модулей, где ухудшение не предполагалось.
Эта метрика помогает анализировать «здоровье» кода, риски модификации и ни в коем случае не может восприниматься как единственно верное знание, отражающее состояние кодовой базы. Однако, она очень быстро поможет выявить места, где требуется рефакторинг с целью уменьшения coupling и увеличения cohesion.
Понимаю, что материал довольно абстрактен, и до этого абзаца мало кто дочитает, но рекомендую просто найти инструмент, натравить его на реальный проект, сгенерировать и изучить отчёт, подтюнить и внедрить. Это гораздо удобнее, чем просто какие-то цифры. Такой подход позволяет изменять что-то в коде и смотреть, как и на что это повлияло. Удачи!
А на этом я заканчиваю, получился очень большой лонгрид. Скорее всего, я вернусь с другими метриками, так как на этой свет клином не сошёлся.